
Hermes gets a notebook the rest of your agents can read
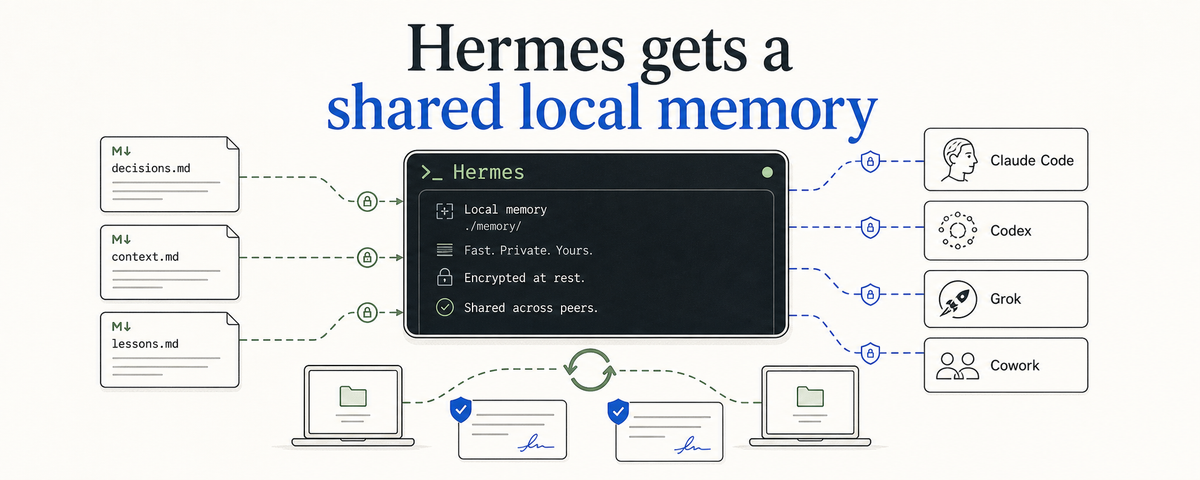
A new Hermes memory provider plugs the Nous Research agent into the same local markdown memory Claude Code, Codex, Grok Build, and Cowork already use. Hermes starts a session knowing what the others learned, and adds back what it learns.
Introducing the Hermes Observational Memory Plugin.
Hermes describes itself as "the agent that grows with you." Most of the framework backs that up. Hermes runs from a terminal, ships with a plugin system, an AGENTS.md convention, a /goal workflow, and a pluggable memory layer. It is one of the more interesting things to come out of Nous Research this year.
What kept tripping me up was that Hermes only grew with itself. It did not grow with the other agents I was using during the same workday.
The Hermes Observational Memory plugin closes that gap. With it installed, a Hermes agent reads from and writes to the same local memory layer that Claude Code, Codex, Grok Build, and Cowork already use. Hermes starts a session knowing what the others learned, and adds back what it learns.
What memory actually means for an agent like Hermes
"Agent memory" is a phrase that means at least five different things right now, so it helps to be precise about which one we are talking about.
Hermes already has memory. The built-in layer is two files in your profile, MEMORY.md and USER.md, that travel with you across sessions. That is enough for a lot of people. If you are running Hermes solo and you only need it to remember your name, your preferences, and a few project rules, you do not need anything else.
The reason Hermes also supports a memory provider plugin system is that the moment the agent has actual work in front of it, two new pressures show up.
The first is volume. A working agent produces more durable signal in a week than two files want to hold. You start wanting search, scoping, and some way to keep recent notes from drowning the stable stuff.
The second is reach. If Hermes is running on a server, or in a long-lived session, or as part of a fleet, you want it to know things it did not learn first-hand. Maybe you had a conversation with another agent on your laptop. Maybe a teammate's machine made a decision you need to honor. Memory becomes a thing that gets shared, not just accumulated.
Hermes already has eight memory providers for this. Most of them are cloud services. Honcho models the user dialectically. Mem0 extracts facts on the server side. Supermemory does context fencing and session graphs. Each is a reasonable answer to "where should this agent's long-term memory live."
Observational Memory is a different answer to the same question. OM puts the memory on your machine, in plain Markdown files you can open in any editor. The same files are the substrate for every agent on that machine. When memory does need to cross machines, it crosses as signed records over a transport you picked, not rows in someone else's database.
That is the option this plugin adds to Hermes.
Why I want this for Hermes specifically
Hermes is built for the case where the agent persists. You leave it running. You hand it a goal. You come back to it tomorrow.
That is the case where a memory layer matters most, and the case where it hurts most when memory is locked inside one product.
Here is the day I actually have. I open Claude Code in the morning and figure out the right release boundary for a refactor. I switch to Codex midday and start cutting the PRs. I let Hermes pick up the long tail on a VM, because that work does not need me in the loop and I want to sleep. None of that is exotic. It is just what using more than one agent looks like.
Without shared memory, Hermes is the new hire who shows up the day after the planning meeting and has to be re-briefed. With shared memory, Hermes opens its session, reads the notebook the other agents already wrote in, and starts work where they left off.
The cost of being the new hire every morning is not abstract. It is the ten minutes you spend re-pasting context, the small decision an agent gets wrong because it never saw the original constraint, the slow drift between what you told one tool and what another one is doing. Memory is the cheapest fix to that drift, as long as you do not have to surrender your context to a vendor to get it.
The install, and the three things Hermes can do once it's installed
The path is two commands:
hermes plugins install intertwine/hermes-observational-memory --no-enable
hermes memory setup
Pick observational_memory when the setup prompt asks which provider to activate.
The --no-enable is deliberate. Memory providers in Hermes are exclusive plugins. Only one is active at a time, and they get selected through memory.provider, not the normal enable list. If you let Hermes enable the plugin the standard way, you end up fighting the setup flow. Small detail, the kind that decides whether someone gets a working install on the first try.
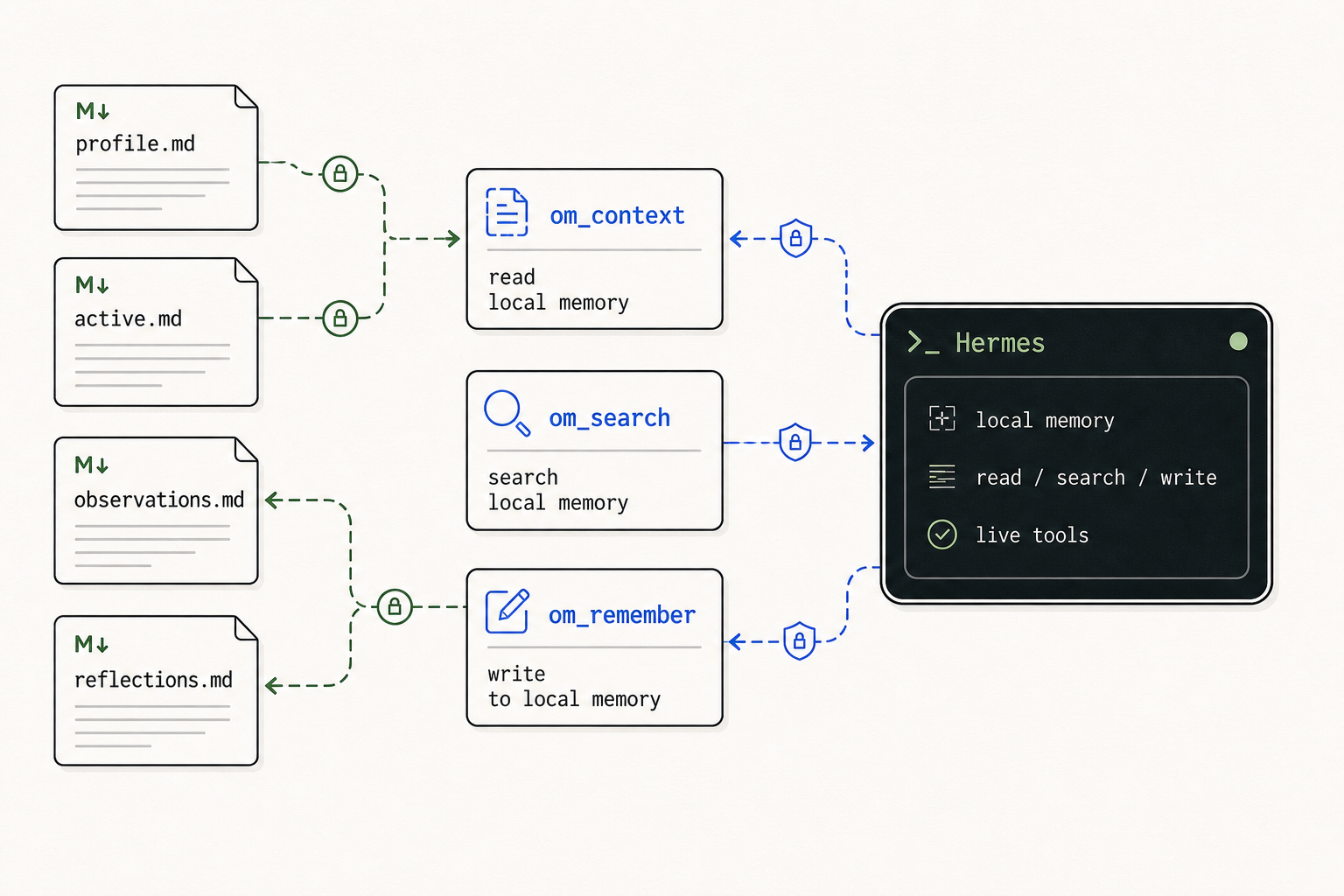
Once it is active, Hermes gets three tools:
om_contextloads a compact startup briefing: your stable profile, your active work, the guardrails you want to survive the session. It can also fetch task-specific recall on demand.om_searchsearches prior observations and reflections.om_rememberwrites a note immediately, before the session ends and before any writeback flow runs.
Those three tools sit on top of four plain files in your home directory:
~/.local/share/observational-memory/profile.md
~/.local/share/observational-memory/active.md
~/.local/share/observational-memory/observations.md
~/.local/share/observational-memory/reflections.md
That is the part I keep insisting on. You can open those files. You can grep them. You can hand-edit them. There is no opaque store and there is no remote service you have to trust. Hermes is reading and writing what Claude Code is reading and writing, what Codex is reading and writing, what Grok Build is reading and writing, what Cowork is reading and writing. One notebook. Many readers.
OM Cluster, for when one machine is not enough
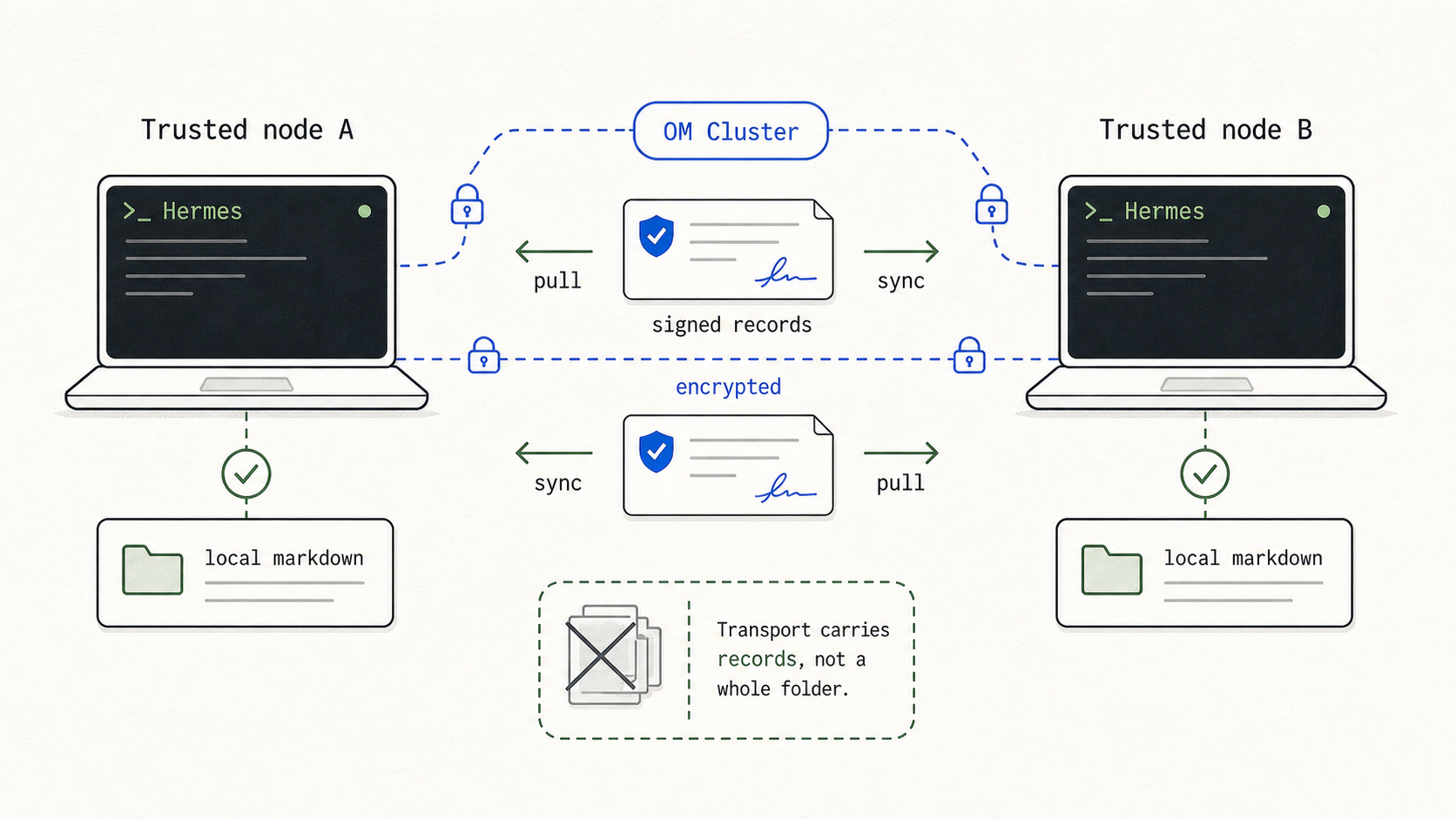
Hermes is the agent I most often run on something that is not my laptop. Sometimes it lives on a VM. Sometimes it lives on a server I share with myself across machines. That breaks the "one local notebook" story unless you have a way for two trusted nodes to share memory without either of them shipping the whole directory around.
OM Cluster is that piece. It is the opt-in sync layer that arrived in Observational Memory 0.6.x. The local Markdown is still the source of truth on each node. Underneath, OM Cluster maintains an encrypted, signed, append-only record stream that moves between nodes over a transport you pick: a shared folder, a relay, a direct peer path. Transport access is not memory trust. A node has to be invited.
The plugin understands cluster mode. When it is on and sync_before_context is true, Hermes asks OM to pull shared records before it reads startup memory. So a Hermes agent on a VM can see a note your laptop's Codex wrote an hour ago, without anyone copying a whole directory anywhere.
Writes go the other direction. With cluster mode on, om_remember writes a signed record, materializes the local Markdown view, and optionally runs a short post-write sync. The notes Hermes contributes show up on your other trusted nodes the next time they pull.
That is the multi-machine shape I wanted Hermes to have. Local-first does not have to mean single-machine.
Why this is a plugin, not a core patch
I tried the other path first. I had a working native Hermes provider PR. It proved the surface was feasible. It also turned out to be the wrong way to ship.
Hermes has moved decisively toward user-installed memory providers. New in-tree backends are not the path of least resistance anymore, and that is the right call by the Hermes team. The plugin shape lets every provider (Honcho, Mem0, OM, whatever comes next) ship on its own schedule against a stable contract.
For OM specifically, the standalone plugin:
- installs into
$HERMES_HOME/plugins/observational_memory; - declares itself as
kind: exclusive; - depends on
observational-memory>=0.6.3,<0.7; - does not need a symlink into the Hermes source tree;
- can cut releases when OM cuts releases, not when Hermes cuts releases.
Agent ecosystems are moving quickly enough that the last point matters more than the others. A memory integration that has to wait on a host release to ship a fix is a memory integration that falls behind.
What I validated before publishing this
Quick note on what is tested and what is not.
I ran the plugin against a clean Hermes checkout from a user plugin directory. It was discovered, loaded as an available memory provider, and reported as an exclusive provider activated through hermes memory setup. That is the current provider contract, not the old source-tree symlink workaround.
The plugin's own test suite covers:
- startup context injection,
- cluster pull-before-context,
- local
om_remember, - cluster-backed
om_remember, - incremental Hermes session writeback,
- safe session-end flushing when a writeback is already running.
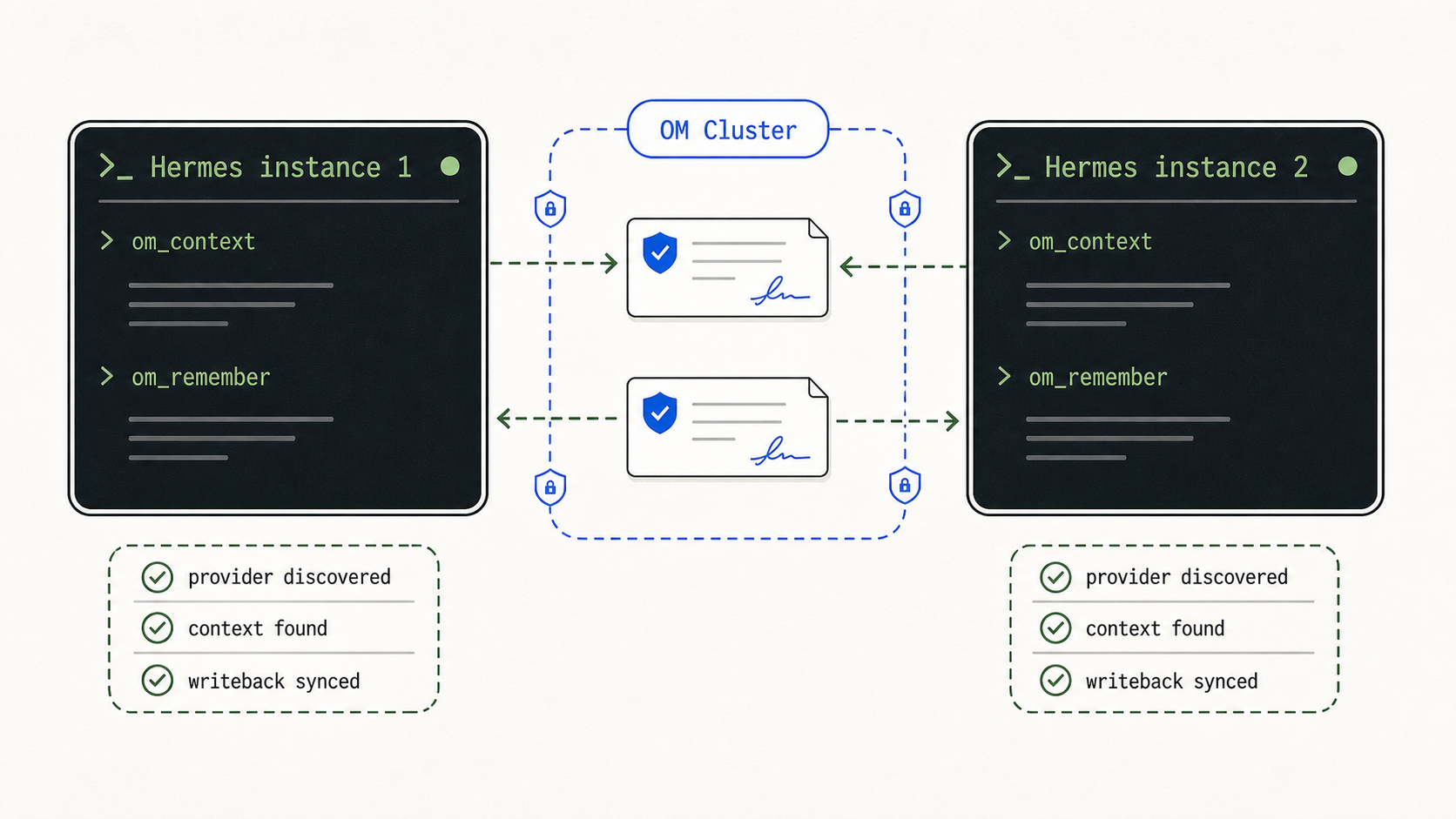
For the cluster path, I ran a smoke test with two OM homes on the same machine pretending to be two trusted nodes. One node wrote a shared observation and synced. The Hermes plugin on the second node pulled before context, found that memory through om_context, wrote a fresh observation, and the first node pulled it back. End to end, in both directions.
That is the behavior I care about most. Hermes can read shared memory and contribute to it.
The operator model has not changed
There is no magic remote memory anywhere in this. If you want Hermes to share memory across machines, you initialize or join a cluster yourself:
om cluster init --name "Personal Memory" --transport filesystem:~/Sync/om-cluster
om cluster invite --expires 10m
om cluster join "omc1:..."
om cluster sync
Then validate the surface you actually plan to use:
hermes memory status
om doctor --validate-key
om cluster status
Inside Hermes, ask it to call om_context, om_search, and om_remember. Confirm what it produced from the other side with om search, or from another trusted node.
That is less glamorous than a memory service that promises to figure all of this out for you. I think it is the right trade. Memory is allowed to be powerful without being mysterious.
Where this puts Hermes in the broader memory layer
Observational Memory is becoming a small shared substrate for local agents:
- Claude Code and Codex get startup context and checkpoints through hooks.
- Grok Build gets native hook support and session observation.
- Cowork gets a local macOS plugin and
/recall. - Hermes now gets a memory-provider plugin that fits its native contract.
- Hosted tools get reviewed export bundles, not silent writes.
The line I keep trying to draw is local continuity first, product-specific bridges second, reviewable boundaries everywhere.
For someone building with Hermes, the practical win is that you stop having to pick between Hermes-flavored memory and the memory your other agents already use. You get Hermes-flavored memory, on top of a notebook the rest of your agents can read.
Hermes was already the agent that grows with you. Now it can grow alongside the others.



