Stop paying per-token. Let your subscriptions share memory.
Observational Memory lets ChatGPT and SuperGrok subscriptions run observation and reflection work on plans you already pay for while giving multiple coding agents one shared local memory layer.

Bottom line: Observational Memory includes om login, which lets you use ChatGPT or xAI subscription-backed inference for the memory work behind observations and reflections while making cross-subscription agent work cheaper, easier, and more efficient.
There is a funny little cost hack floating around agent Twitter right now. A recent AVB post captured it perfectly: if a $20 coding-agent subscription is not enough, maybe the answer is not the $100 tier. Maybe the answer is a second $20 subscription.
That is clever. It is also incomplete.
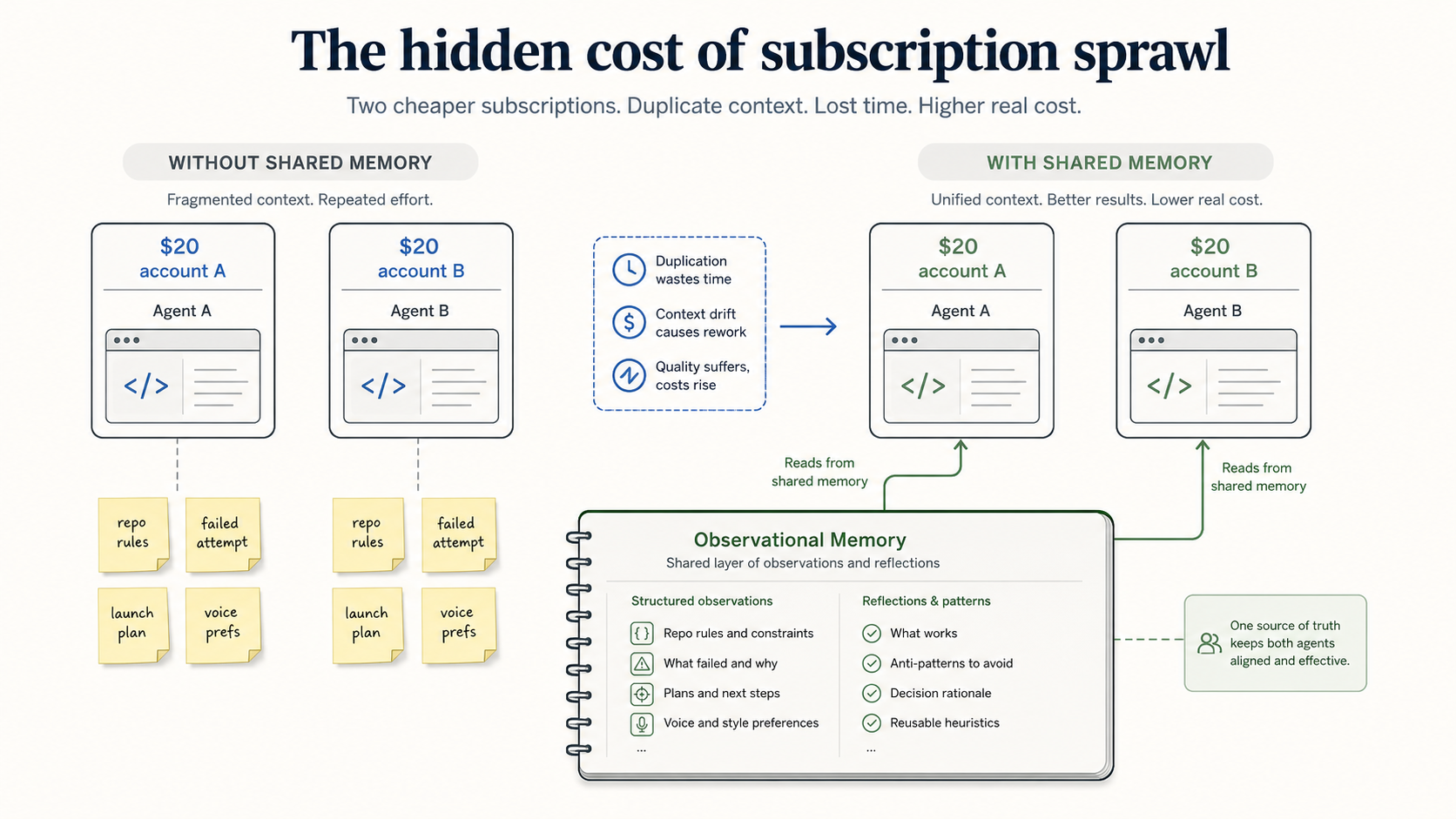
The hidden cost of the two-subscription setup is memory. The second account does not know what the first account already learned. It does not know the repo conventions, the local guardrails, the failed attempts, the launch plan, or the phrasing you already rejected. So you pay in a different currency: pasted context, repeated explanations, wasted turns, and agents that make the same mistake in two places.
The most annoying line item in agent work is not always the visible subscription price. Sometimes it is the background memory work that keeps every session from waking up cold. A background observer compresses a transcript. A scheduled reflector rewrites the long-term notes. A startup hook stitches together a 24KB context pack the moment a new session begins. None of those calls feel expensive while you are writing them. They feel expensive when the cheap-feeling features run ten times an hour.
This is the subscription-auth path in Observational Memory: the meter stops running on background memory work, and the cheaper multi-subscription path starts making more sense.
om login provides first-class flows for the two ecosystems that publish a subscription-backed inference path the way Codex CLI and Grok Build TUI already use:
- OpenAI ChatGPT (Plus / Pro / Team / Enterprise) via the Codex OAuth device-code flow.
- xAI Grok (SuperGrok) via the OIDC authorization-code + PKCE loopback flow.
Both are zero-marginal-cost calls on a plan you already pay for. Existing API-key paths (anthropic, openai, plus the metered xai API-key path) keep working unchanged. The only thing that changes for you is that the cheap-feeling features now actually are cheap.
The current cost problem is subscription sprawl
The old agent-cost problem was simple: every observation, reflection, summary, and recall was another API call. If you wanted real memory, you either accepted the meter or turned the memory features down until they stopped helping.
The current cost problem is stranger. Many builders now have subscription access to more than one strong coding model: ChatGPT/Codex for one workflow, Grok Build or SuperGrok for another, Claude Code somewhere else, maybe a second account when quota gets tight. The bill can be lower than one top-tier plan, but the context becomes fragmented.
Observational Memory treats memory as the shared layer between those subscriptions. om login openai-chatgpt lets the observer and reflector use your ChatGPT subscription. om login xai-oauth lets the same memory loop use your SuperGrok subscription. The observations and reflections still land in one local, inspectable memory store that Codex, Claude Code, Grok Build, Hermes, Cowork, and other agents can read from.
That is the practical angle: you are not pooling provider quotas or bypassing terms. You are making the memory work run on subscriptions you already pay for, while keeping the result portable across the tools and accounts you legitimately use.
If your choice is "$100 for more headroom" or "two cheaper subscriptions and some discipline," the missing discipline is shared memory. Without it, the second subscription spends its cheap turns rediscovering what the first one already knew.
Since this article first shipped, the subscription-auth path has become part of a broader trust arc. v0.7.0 made reflection section-targeted, so large memories patch the sections they touch instead of rewriting the whole file. The current public release, v0.8.0, adds backup/restore, section provenance, scope governance, conflict surfacing, om talk, and an experimental OM Mail preview for signed, encrypted agent-to-agent memory exchange. The cost story is still the same, but the memory loop is now more recoverable, more auditable, and better behaved as it grows.
The 30-second quickstart
If you already have om installed:
om login openai-chatgpt # device-code, opens auth.openai.com
# or
om login xai-oauth # loopback PKCE, opens auth.x.ai
om login writes a single host-local file at ~/.config/observational-memory/auth.json (0600, owner-only), and that is the entire UX. The next time the observer or reflector runs, it picks up the subscription tokens and routes the call through chatgpt.com/backend-api/codex or api.x.ai/v1. The OpenAI SDK handles both — the OAuth access token "looks like" an API key to the client, which is exactly how Codex CLI and Grok Build TUI already use it.
If you have one of those CLIs installed, the import is even shorter:
om login --import
That reads ~/.codex/auth.json and ~/.grok/auth.json if they exist, copies the tokens into om's own store, and never writes back. om refuses to touch upstream CLI state. Your Codex session and your om session keep separate refresh tokens.
What the security model actually says
Two of these flows are routed through inference endpoints whose bearer tokens are high-value, long-lived credentials. So the obvious questions are: where do they live, what can leak them, and what happens when something goes wrong.
Where they live. A single file at ~/.config/observational-memory/auth.json, created with O_EXCL to close the TOCTOU window where a default umask would briefly expose tokens at 0644. Cross-process file lock via fcntl on POSIX, msvcrt on Windows, 10 second timeout. Tokens are never printed to stdout or logs; om auth status redacts to the last four characters.
What can leak them. The xAI inference base URL is the obvious exfiltration vector — a tampered OM_XAI_OAUTH_BASE_URL=https://attacker.example/v1 would ship the bearer to a third party on every reflection. om pins that base URL to *.x.ai on every read, refuses non-HTTPS overrides, and falls back to the default with a warning rather than raising. The OIDC token_endpoint from the discovery doc is pinned the same way, on every refresh, so a one-time MITM during initial login cannot become a permanent credential leak.
What happens when something goes wrong. An HTTP 403 from the xAI token endpoint is almost always a subscription tier denial (SuperGrok base tier vs. the OAuth-allowlisted tiers). om catches that specific case and tells you to switch to OM_LLM_PROVIDER=xai with an XAI_API_KEY, rather than the usual "re-authenticate" hint that would never have fixed anything. A refresh_token_reused from OpenAI — typical when Codex CLI or the VS Code extension rotated the same refresh token in another window — surfaces with a one-line explanation of what just happened.
A note on credit
The xAI loopback flow is not a from-scratch implementation. It is a verbatim port of the upstream Hermes (nousresearch/hermes-agent) hermes_cli/auth.py work, blob 5fd3676 from 2026-05-23. That includes:
- the
plan=genericworkaround for theaccounts.x.aiallowlist - the S256 PKCE flow with the
code_challengeechoed at the token step, which fixes thecode_challenge is requiredquirk in xAI's token endpoint (upstream issue #26990) - the
*.x.aihost-pinning on discovery and inference base URL - the CORS handler on the loopback server that lets the consent screen's success script dismiss the tab
- the manual-paste fallback for SSH, Cloud Shell, and Codespaces, where the loopback listener can't reach the user's browser
- the HTTP 403 →
xai_oauth_tier_deniedmapping with the metered-fallback recommendation
The ChatGPT path leans on Hermes too. The Codex backend behind chatgpt.com/backend-api/codex is not a plain Chat Completions endpoint — it sits behind Cloudflare, speaks the Responses API, and only accepts requests that advertise a first-party originator. Hermes's _codex_cloudflare_headers (the originator: codex_cli_rs / ChatGPT-Account-ID trick) is what gets a non-residential machine past the Cloudflare challenge, and om ports it directly. Bringing this up live surfaced a chain of backend quirks — the model allow-list shifts, the request must stream, store must be false — each of which is now handled and documented in the release notes.
Each ported module in om has a header comment that cites the upstream file and blob SHA so future maintainers can pull bug fixes directly. The Hermes team did the hard part — finding the quirks, documenting them, and shipping a working flow. om just gives the same hardened flow to people who are not running Hermes today.
What still uses metered paths
Anthropic does not currently publish a third-party-client inference endpoint, so Claude Pro / Max subscription auth is still not available through om. If you primarily use Claude through om, the cheapest path remains the existing ANTHROPIC_API_KEY flow with a low-cost model.
Usage and budget tracking are no longer future work. om usage status, om usage tail, and om usage budget record host-local token, cost, and latency rows, and subscription-backed calls show estimated cost as $0.00. OpenAI Batch also exists for direct openai API-key reflection through om reflect --async and om jobs; it does not apply to the openai-chatgpt subscription provider.
Try it
uv tool upgrade observational-memory # or brew upgrade observational-memory
om login # interactive picker
om auth status
om doctor # confirms 0600 auth.json + redacted token tail
om usage status # shows local usage, budgets, and $0.00 subscription calls
If you have any feedback — what broke on your machine, what the picker should call your provider, what the doctor check should warn about — open an issue at github.com/intertwine/observational-memory or drop me a note. I am especially interested in hearing from anyone who hits an xAI tier-denied response, because that one is fixable with a clearer error message but I want to know what the symptom looks like in the wild.