
Building ClawFleet Academy, an ops control plane for agent fleets
I am building an operations layer for a fleet of strong AI agents. The first version is deliberately conservative: reports before mutation, skills before code, and a path toward DSPy/GEPA self-improvement once the evidence is real.
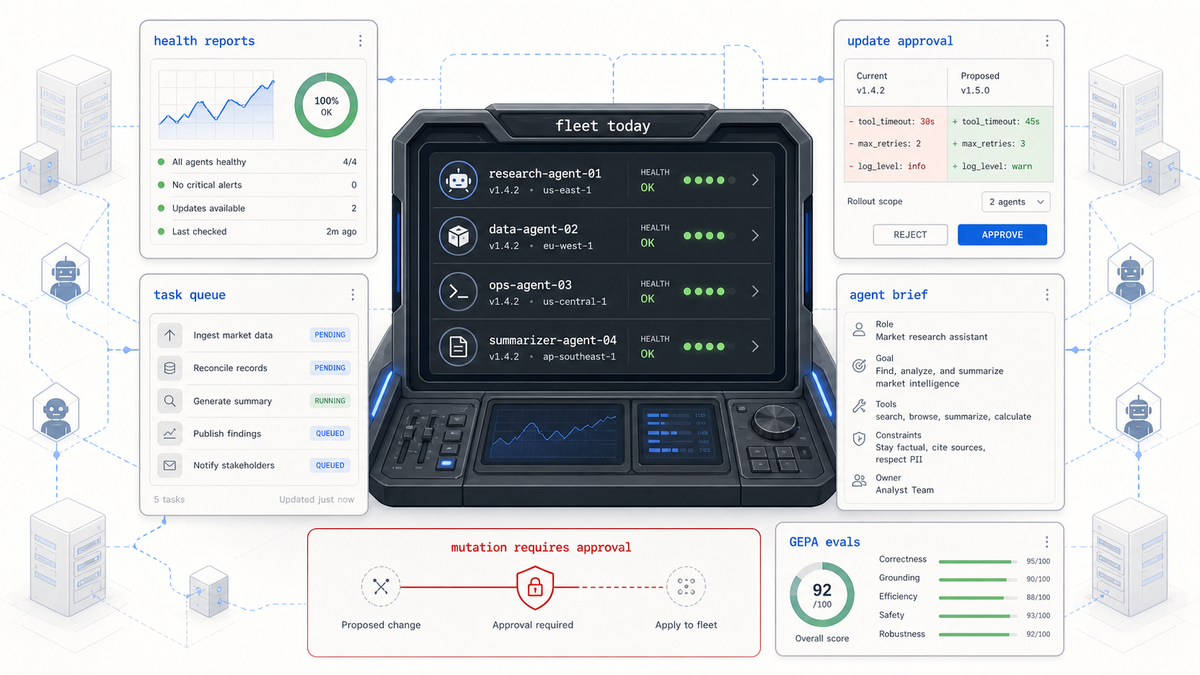
I am building an operations layer for a fleet of strong AI agents. Not a dashboard first. Not an everything-autonomous magic box. A boring control plane that knows what is healthy, what is drifted, what is allowed, what needs approval, and what should be learned from the last run.
For the last several days I have been building a private project called ClawFleet Academy.
The name is half joke, half useful metaphor. It is an academy for a small fleet of capable agents: OpenClaw bots on one machine, Nous Hermes agents on several others, and a local control plane whose job is to keep them healthy, current, secure, observable, and improving.
The public version does not exist yet. The private repo contains live topology, private reports, operational history, and machine paths. I would not publish it as-is. The thing I do want to publish later is the framework underneath it: skills, schemas, status contracts, scheduler patterns, update gates, task queues, and eventually DSPy/GEPA examples that help other people build their own version.
This article is the first field note.
Why an agent fleet needs ops
A single chat session can be managed by vibes. A fleet of agents cannot.
Once agents are running on machines, talking to Slack or Telegram, updating their own repos, scheduling tasks, and choosing work independently, the problem changes. The question is no longer "can the model answer this prompt?" It becomes:
- Is the service alive?
- Is the host healthy?
- Is the agent behind upstream?
- Are its tasks stuck?
- Is an update safe to plan?
- Has a dry-run happened?
- Did the user actually authorize mutation?
- What did we learn that should change the next run?
That sounds like regular ops because it is regular ops. The twist is that the things being operated are themselves agents.
I do not want the control plane to absorb the work of the fleet. OpenClaw and Hermes are full agents. They should keep working independently. The control plane should mostly care about the conditions that let them work well: health, auth, updates, security, queues, evidence, task status, and feedback loops.
The sharp line is important. ClawFleet Academy should not become a supervisor that reads every autonomous task and judges its business value. It should manage ops-assigned work, preserve the fleet's ability to act, and improve the system that keeps the agents reliable.
The current fleet
The live private fleet currently has four main targets:
- one OpenClaw VM hosting several bots, including the main Volta agent, Aria, Polymarket Ops, Content Scout, Writer, and Poster;
- a Hermes VM;
- an ACIBF Hermes VM;
- a macOS Hermes peer called Candlelight.
The control plane runs from a local repo and a GCP runner VM. The runner owns scheduled reports. Tailscale and ordinary SSH are the management substrate. GCS stores the append-only report artifacts. The repo stores the contracts, runbooks, skills, policies, schemas, examples, and dated interpretation notes.
The architecture is intentionally not clever. The control plane has a unified fleet registry, small Python scripts, shell wrappers, systemd timers, local skills, and reports. Platform-specific knowledge stays where it belongs: OpenClaw ops in the OpenClaw repo, Hermes ops in the Hermes skill bundle, fleet-level contracts in ClawFleet Academy.
That boundary has already paid for itself. When OpenClaw was degraded by disk pressure and stale health evidence, the fix was not a sweeping rewrite. The runner surfaced the issue, I cleaned safe caches and logs, hardened the health temp-file path, and recorded the evidence. Root disk dropped from 92% used to 83%. Health returned green. The next action became update planning, not incident triage.
That is what I want from the tool: small, grounded, operational moves.
The rule: report before mutate
The current update path is a state machine:
readiness -> update-action -> executor dry-run -> approval -> execute -> postchecks
Each arrow has a report artifact behind it.
update-readiness joins current health with update drift. If a target is unhealthy or unreachable, it should not slide forward just because an upstream version exists.
update-action creates a dry-run contract for one target. It includes the rollback note, command plan, source reports, and stop conditions. Creating this artifact does not mutate the target.
update-execution can run in dry-run mode or real execution mode. Dry-run mode records exactly what would happen. Real execution still requires explicit authorization and postchecks.
update-approval watches the evidence and tells the operator what state each target is in:
needs_action_contract
action_contract_ready
pending_operator_approval
execution_recorded
no_update
readiness_unknown
The most important thing here is not the command. It is the refusal to collapse different meanings of "ready."
Green health means the service is healthy. Drift means the service is healthy but behind upstream. Dry-run green means the command plan can be simulated. None of those mean "go mutate the fleet."
That distinction is the difference between a tool I trust and an agentic footgun with a pleasant UI.
The cockpit came before the dashboard
I like dashboards, but I did not start there.
The first useful interface is a command:
make fleet-today
It shows a per-device view, not just a fleet summary. Summaries hide the thing you need to fix. The current runner-backed output looks like this:
# Fleet Today
Fleet Status: drift
Evidence Status: drift
Source: cache:catalog+gcs (9 records)
Devices:
Target Status Health Update Host Tasks Next
------------------------ --------- --------- ---------------------- --------- -------- ----------------------------
openclaw:openclaw-vm drift green needs_action_contract green green create update-action
hermes:hermes drift green needs_action_contract - green create update-action
hermes:acibf drift green needs_action_contract - green create update-action
hermes:candlelight drift green needs_action_contract - green create update-action
That is the shape I want. Four devices. Health green. Update drift. The next action is explicit.
The runner precomputes a fleet-current-state.json file from the hot report catalog. That makes the interactive path fast: on the runner, cached fleet-today returned in about 0.08 seconds, fleet-action in about 0.09 seconds, and agent-brief in about 0.10 seconds. Manual refresh can still go back to GCS evidence when I want authority over speed.
This split matters. Expensive evidence collection belongs on a schedule. Operator UX should be instant enough that people and agents actually use it.
From status to action
The next command is:
make fleet-action ARGS="--target hermes:candlelight"
For the current Candlelight state, it renders the non-mutating update-action command:
python3 scripts/reporting.py update-action \
--target hermes:candlelight \
--rollback-note 'If the Hermes update fails, inspect updater output and worktree state, restart the gateway, restore 8ed599dc0546 only with explicit approval, then rerun hermes doctor/status postchecks.' \
--approved-by agent-ops-control
The command is generated from the same state object as fleet-today. There is no separate "dashboard truth" and "CLI truth." The action surface is just the cockpit state made executable.
That is the pattern I want everywhere:
- health state maps to a health action;
- drift state maps to an update contract;
- action-contract state maps to executor dry-run;
- pending-approval state maps to asking a human for explicit authorization;
- degraded or unknown state maps back to evidence collection and remediation.
Small state machine. Typed states. Boring commands.
Agent briefs
The control plane can also write a compact brief for a target:
make agent-brief ARGS="--target openclaw:openclaw-vm"
It contains:
- mission;
- boundaries;
- evidence;
- recommended plan;
- report-back contract.
That brief can be handed to another ops agent, dropped into a target-local task queue, or used as a one-shot invocation prompt. The important part is that the agent gets the same evidence and boundaries a human operator sees.
For now, the task queue is deliberately scoped to origin: agent-ops. The control plane is responsible for tasks it assigns or adopts. It is not trying to supervise everything the agents decide to do on their own.
This is where I think most "multi-agent orchestration" systems get too eager. They make the manager agent central. I want the opposite: a small control plane that helps capable agents stay healthy and report back clearly.
Skills first, code supported
One of the design rules in ClawFleet Academy is:
skills first, code supported
Judgment belongs in skills and runbooks when possible. Code belongs where there is an operational contract to enforce.
Keep in code:
- state transitions;
- schemas;
- leases;
- status classification;
- mutation-policy validation;
- report upload and readback;
- normalized evidence adapters.
Move to skills and runbooks:
- target-specific update recipes;
- recovery decision trees;
- "why this action is safe";
- rollout checklists;
- reflection prompts.
This keeps the repo from turning into a giant Python control system full of prose decisions. It also makes the framework more portable. A future public ClawFleet Academy should not know my machines. It should teach your agent how to build a registry, write reports, gate mutations, delegate safely, and learn from operations.
The part that feels new
The ops pieces are familiar. The self-improvement loop is where this gets interesting.
Every report the control plane writes is potential training data:
- a health report that classified a real outage;
- an update-readiness report that blocked a risky update;
- a task-status report that caught a stale lease;
- an approval queue state that selected the right next action;
- a remediation report that fixed disk pressure;
- a user correction that changed a runbook;
- a failed assumption that became a test.
The mistake would be to throw GEPA at the whole system too early. I do not want an optimizer making live mutation decisions. I want it improving the judgment surfaces around those decisions.
The first DSPy programs should be narrow:
- classify a fleet state into the next safe action;
- generate an agent brief from device evidence;
- propose a remediation plan from a host hygiene finding;
- summarize report evidence without hiding per-device truth;
- decide whether a completed ops-assigned task is ready for verification.
Each of those has a metric. Not a vibe metric. A real one.
For example, a next-action classifier can be scored on:
- target identity preserved;
- mutation policy respected;
- evidence cited;
- no degraded target promoted to update execution;
- no dry-run treated as authorization;
- correct next state transition.
An agent-brief generator can be scored on:
- includes mission, boundaries, evidence, plan, report-back;
- does not expose secrets;
- names the right target;
- avoids supervising out-of-scope autonomous work;
- preserves the difference between read-only, dry-run, and mutating steps.
That is exactly the kind of problem DSPy is good at: turn "write a good brief" into a typed program with a metric. Then GEPA can improve the instructions by reflecting on concrete failures.
I have already been working in this direction with dspy-agent-skills. In Inside the examples: how GEPA lifted a 1.2B model by 25 points, the important lesson was not the score. It was the feedback shape. GEPA only works when the metric can explain what failed.
Fleet ops gives us that feedback naturally, if we preserve it.
The GEPA loop I want
The eventual loop looks like this:
real ops run
-> structured report
-> example row
-> DSPy program prediction
-> rich-feedback metric
-> GEPA optimized candidate
-> shadow evaluation beside current rules
-> promotion into skill, policy, or code
The promotion step matters.
If the optimized program learns a better explanation pattern, that should probably become a skill update. If it learns a stable transition rule, that may become code plus tests. If it learns a better checklist, it belongs in a runbook. The optimizer should not become an untouchable blob at the center of ops.
I want the control plane to learn, but I also want the learning to become inspectable artifacts.
This is where "self-improving" can be made less mystical. The system observes real operations, extracts examples, optimizes a judgment module, proves it in shadow mode, and then lands the useful behavior in the repo.
Why not start fully autonomous?
Because "fully autonomous" is a bad first milestone.
The current system can already keep reports fresh, surface drift, generate update contracts, prepare agent briefs, and tell me the next safe step. It can also avoid doing the wrong thing. That is enough autonomy to be useful.
I would rather have a conservative runner that never silently crosses an authorization boundary than a flashy one that sometimes does.
The plan is to expand autonomy through policy gates:
- unattended read-only monitoring;
- unattended cache/index refresh;
- unattended dry-run contract generation;
- approval-gated executor dry-runs;
- explicit-authorized mutation;
- eventually, narrow unattended mutation for low-risk classes after enough evidence.
Each step needs reports, tests, rollback stories, and postchecks.
What gets open sourced
The current private repo is not the product.
The future public artifact should be a scrubbed framework:
- fleet registry schema;
- status vocabulary;
- report JSON contracts;
- systemd and launchd scheduler templates;
- task queue envelope;
- mutation policy examples;
- skills for fleet ops, update readiness, action contracts, task queues, and self-improvement loops;
- DSPy/GEPA examples trained on sanitized ops scenarios.
The goal is not to sell "my exact fleet." It is to give people a working pattern for their own agent fleets.
If you run one coding agent, this may sound overbuilt. If you run several strong agents across machines, it starts to feel like table stakes.
Where this goes next
The next private milestones are straightforward:
- create current update-action contracts for the drifted fleet;
- keep the runner green and fast;
- turn repeated incidents into eval rows;
- build the first DSPy classifier for ops triage;
- run GEPA on real examples;
- compare the optimized judgment module against the current deterministic rules in shadow mode.
When that loop works, the launch series gets more interesting. Then I can write with outcomes: what GEPA improved, what it failed to improve, which skills changed, and which parts of agent ops should stay deterministic forever.
For now, the thing I am happiest about is smaller:
make fleet-today
Four devices. Typed state. One next action each.
That is not the end state of autonomous agent operations. It is a good beginning.



