
Inside the examples: how GEPA lifted a 1.2B model by 25 points
Three end-to-end runs on free OpenRouter models. Real baselines. Real optimized scores. The counterintuitive reason why a smaller task LM exercises GEPA better than a bigger one.
The dspy-agent-skills repo showcases three end-to-end example runs on no-cost OpenRouter models. Real baselines. Real optimized scores. The counterintuitive reason why a smaller task LM exercises GEPA better than a bigger one. Read on to reproduce the results for yourself (for free).
https://github.com/intertwine/dspy-agent-skills
The committed numbers
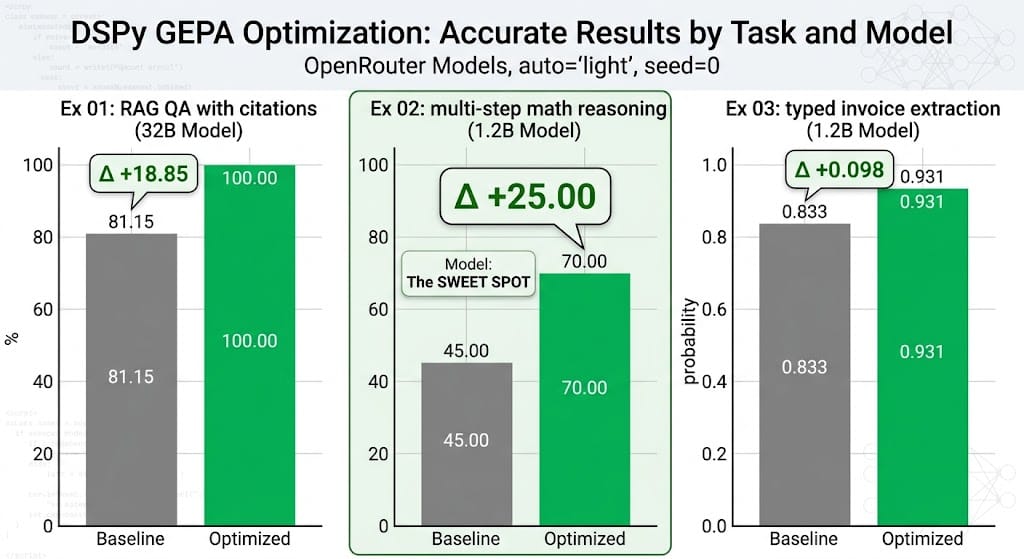
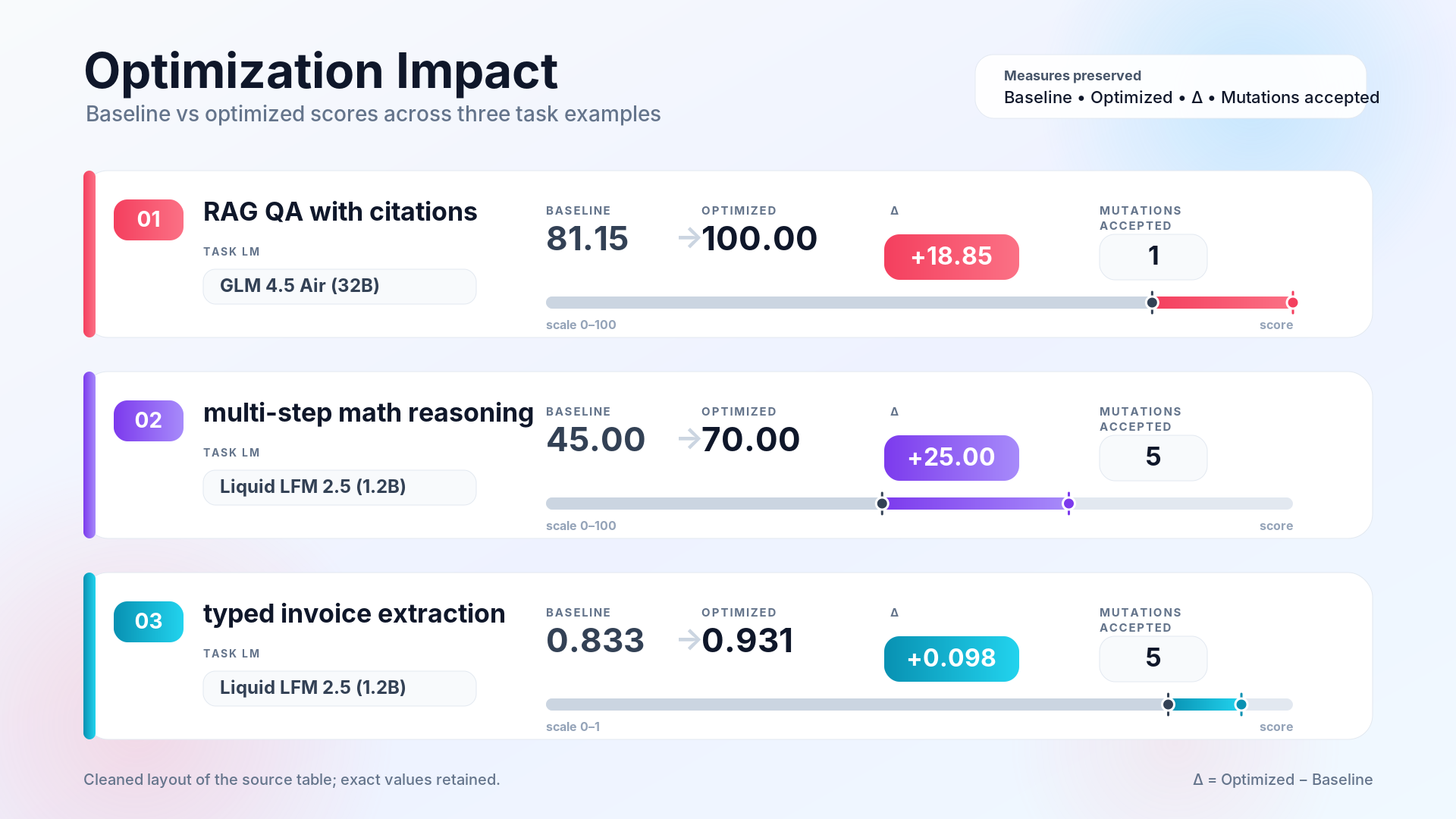
Three examples. All three runs used auto="light" and seed=0, free OpenRouter models only, a single reflection LM (Nemotron-3-super-120B-a12b). Total spend to reproduce: zero dollars if you stay inside OpenRouter's free tier.
Caveats you should hold in your head while reading the rest. These are single-seed runs on small train/val splits (15–34 train, 9–12 val). They're toy-but-real demos, not a benchmark. Free-tier provider behaviour shifts over time, so a re-run won't be perfectly deterministic; expect a few points of drift. For rigorous numbers, the GEPA paper and the DSPy AIME tutorial are the right references.
I'll walk each example top-to-bottom, then end with the saturation lesson that forced me to pick a 1.2B task LM for two of them.
Example 01: RAG QA with citations
The task. Twelve short articles about the solar system (one per planet plus a few moons). Twenty-five labeled questions split fifteen-train / ten-val, each with a single authoritative source. The program retrieves top-3 passages via BM25, then passes them to a dspy.ChainOfThought that must emit both an answer and the doc IDs it used as evidence.
class AnswerWithCitation(dspy.Signature):
"""Given retrieved passages, answer the question concisely and cite the
passage IDs used as evidence."""
context: str = dspy.InputField()
question: str = dspy.InputField()
answer: str = dspy.OutputField(desc="short, factual answer — no prose padding")
citations: list[str] = dspy.OutputField(desc="doc IDs from the context that support the answer")
The metric. Three weighted axes:
- Correctness (weight 0.55): fuzzy substring or token-overlap match against gold.
- Citation validity (0.30): at least one cited doc ID is in the gold set; extras are penalized.
- Conciseness (0.15): 3–25 words, penalty either side.
The metric returns dspy.Prediction(score, feedback) where feedback names the failing axis with specifics. That's what lets the reflection LM learn what to fix.
What GEPA did. Iteration 1 produced an instruction that scored perfect on the full valset. GEPA spent the rest of the budget correctly refusing to mutate. Every subsequent minibatch was all-correct, so there was no signal. The final optimized_program.json is a 2.4 KB state file you can load in a separate Python process:
import dspy
dspy.configure(lm=dspy.LM("openrouter/z-ai/glm-4.5-air:free", ...))
program = RagQA(retriever=BM25Retriever(docs))
program.load("optimized_program.json")
print(program(question="What is the orbital period of Mars?").answer)
# → '687 Earth days'
The improvement (+18.85 points) came from GEPA teaching the synthesizer to consistently emit citations even for questions where the model "knew" the answer from pretraining. That's a format problem, not a knowledge problem. Exactly the kind of thing prompt optimization was built for.
Example 02: multi-step math reasoning
The task. Thirty-four grade-school word problems with compound percentages, work-rate problems, weighted averages, and distractor-laden setups. The program is a plain dspy.ChainOfThought("problem -> answer"). No tools, no external data, just reasoning.
Each data point ships a trap field: a one-line description of the common mistake. The metric uses it in feedback so the reflection LM learns structural fixes (step enumeration, unit tracking) rather than memorizing individual answers.
{
"problem": "A $200 item is marked up 25%, then discounted 20% on the marked-up price. What is the final price?",
"answer": 200,
"trap": "200*1.25=250, 250*0.8=200. The sequence matters; do NOT add the percentages."
}
Why a 1.2B model. This is where the saturation story starts. I ran the example first with GLM 4.5 Air (32B). Baseline: 83.33%. Ran it again with Ministral 8B. Baseline: 93.33%. Both runs accepted zero mutations. Every GEPA minibatch was all-correct, so the reflection LM was never called.
The issue isn't GEPA. Modern 8B-plus open-weight models have effectively saturated grade-school word problems. To actually see GEPA improve a program, I needed a task LM that fails on enough examples for there to be signal. Liquid LFM 2.5 (1.2B) fit the bill: baseline 45.00%.
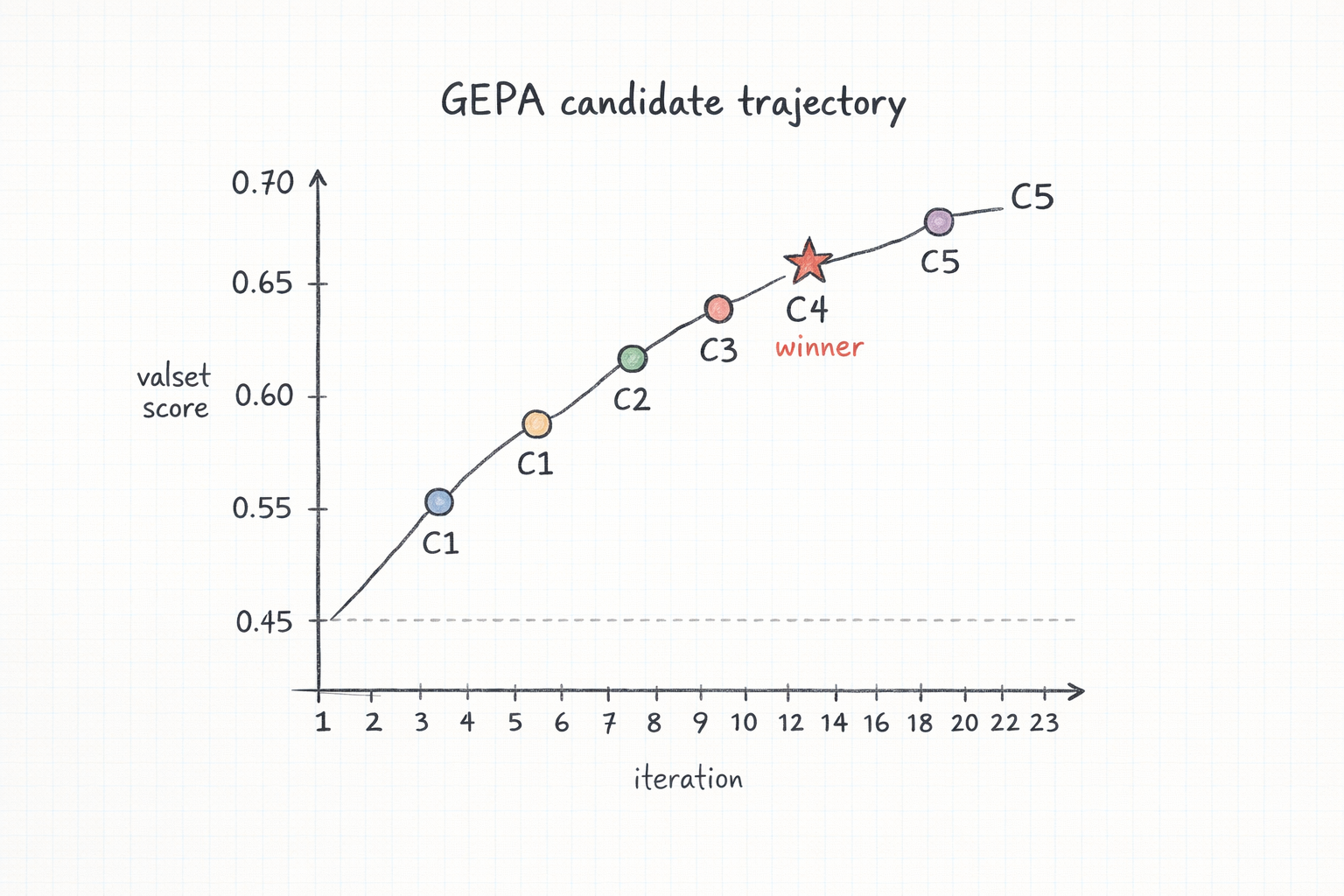
What GEPA did. Twenty-three iterations. Five accepted mutations (at iters 2, 3, 4, 6, 10). Candidate 4 hit the final valset score of 70.00%: a 25-point improvement entirely from rewriting the ChainOfThought instruction. The final instruction prescribes explicit step numbering, unit tracking, and a verification pass before committing the final number.
Total time: ~23 minutes on the free tier with num_threads=1.
Example 03: typed invoice extraction
The task. Pull a typed InvoiceRecord out of unstructured invoice text: vendor, date (normalized to YYYY-MM-DD regardless of source format), line items with description/quantity/unit_price, and final total (after tax/shipping/discounts). The output is a Pydantic model:
class InvoiceRecord(BaseModel):
vendor: str
date: str
line_items: list[LineItem]
total: float
The program is a dspy.ChainOfThought("invoice_text -> record: InvoiceRecord"). DSPy handles the Pydantic serialization round-trip automatically.
The metric. Five axes: schema validity (0.20), vendor match (0.15), date match (0.15), line-item F1 (0.35), total match (0.15). Feedback calls out each failing axis with specifics. F1 is computed on the set of (fuzzy_description, quantity, unit_price) triples, so collapsing two rows into one or splitting one row into two gets penalized as you'd expect.
The data traps. To prevent the same saturation I hit on ex02, I wrote invoices with deliberate gotchas:
- Dates in DD-MM-YYYY, "March 8, 2024", and "22 September 2024" formats.
- Headers with both a seller (vendor) and a distinct bill-to / shipper entity. The gold extraction always wants the seller.
- Discount and rebate rows that reduce the total but are not line items.
- Freight and handling lines that are also not line items.
- Tax-inclusive vs. pre-tax totals where the model has to pick the right "final" number.
What GEPA did. Five accepted mutations, final valset score 0.931 (baseline 0.833, +0.098). The winning candidate's instruction explicitly tells the extractor to pick the FROM: block's entity as vendor, to exclude freight/handling from line_items, and to use the most terminal total in the text.
Total time: ~36 minutes. This run exhausted OpenRouter's 2000 req/day free cap right before the final re-eval. The committed scores are GEPA's own cached full-valset evaluations (used for candidate selection), which is what you'd want: the same number GEPA optimized against.
The saturation lesson
Two out of three examples use a 1.2B-parameter task LM. That's deliberate.
GEPA shines when there's signal to work with. If the baseline is already 0.95 on a task, every minibatch GEPA samples is all-correct, the reflection LM is never called, and the optimizer correctly no-ops. This is not a bug. It's GEPA's designed behavior: don't propose changes when there's nothing to improve.
But for a demo, a no-op is a boring story. So I went looking for a task-model/task combination that produced enough failure signal for GEPA to actually exercise. Most of the smaller free-tier models I tried had disqualifying problems: Gemma 3 4B on OpenRouter rejects system prompts outright, and several others hit structural format-output limits that make Pydantic-typed extraction impossible. Above 8B, grade-school math and typed extraction are already solved. Liquid LFM 2.5 at 1.2B was the smallest free-tier model I could find that still accepts the DSPy prompt shape, and it ended up being the sweet spot for this demo.
The practical implication: if you run the pack and see baseline == optimized, check the difficulty of your data relative to your task LM. Either harden the data, weaken the task LM, or accept that the task is solved and spend your optimization budget somewhere that matters. Arize's independent benchmark of GEPA against other optimizers makes the same point with different wording: optimizer choice matters less than metric quality and task difficulty.
The $0 reproducibility promise
Every committed number in the table above came from a single run with seed=0. The model choices are captured in each example's results.json. The optimized programs are committed as optimized_program.json alongside the source, so you can load and re-score them against fresh data without re-running GEPA. (Seeding does not guarantee bit-exact reproducibility here: free-tier endpoints don't expose deterministic sampling, so a fresh run with the same seed will drift a few points.)
To reproduce:
git clone https://github.com/intertwine/dspy-agent-skills
cd dspy-agent-skills
cp .env.example .env # fill in OPENROUTER_API_KEY
cd examples/02-math-reasoning
DSPY_TASK_MODEL=openrouter/liquid/lfm-2.5-1.2b-instruct:free \
uv run --with dspy --with python-dotenv \
python run.py --optimize --auto light --seed 0
About 20–45 minutes depending on free-tier congestion. Expect a few points of drift from the committed numbers (see the caveats at the top).
What the examples aren't
The point of the three demos is to show the shape of a GEPA loop end-to-end on a single machine in under an hour, not to claim state-of-the-art on any task. For rigorous benchmark comparisons, the GEPA paper is the source and the DSPy AIME tutorial shows a proper benchmark run.
Next
Where dspy-agent-skills goes next sketches the composition patterns I'm most excited about: RLM inside a GEPA-optimized module, multi-agent workflows where one program optimizes another, and production deployment patterns that take a saved program into a real service.



