
Why I built dspy-agent-skills
DSPy turns prompts into programs. GEPA optimizes those programs without RL. RLM reasons over inputs bigger than any context window. dspy-agent-skills packages that workflow for coding agents.

DSPy turns prompts into programs. GEPA optimizes those programs without RL. RLM reasons over inputs bigger than any context window. None of this lands in your coding agent by default, so I packaged it as five skills that do.
The gap
I spent a week this April trying to get Claude Code and Codex CLI to write idiomatic DSPy code. Every session started the same way: I'd paste a paragraph explaining signatures, modules, and why GEPA wants rich metric feedback. The agent would nod, produce something plausible-looking, and silently use a deprecated import or return a dict from its metric in a way that crashes dspy.Evaluate.
The research was all there. The tooling was all there. The docs were all there. What was missing was a curated, spec-compliant way to hand an agent the relevant knowledge once, the way you'd onboard a new teammate.
That's what dspy-agent-skills is. Five Agent Skills that give any compatible coding agent working knowledge of idiomatic DSPy. Tested today against Claude Code and Codex CLI; compatible with the growing ecosystem around the spec.
The three ideas behind it
DSPy - programming, not prompting
DSPy came out of Stanford NLP in October 2023 (Khattab et al.) with a deceptively simple thesis: stop writing prompts by hand, start writing programs that compile down to prompts. Declare the input/output contract as a typed Signature. Compose Modules. Let an optimizer tune the actual prompt strings and few-shot examples for you.
The payoff, from the original paper: DSPy pipelines "outperform standard few-shot prompting (generally by over 25% and 65%) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%)" on GPT-3.5 and Llama2-13B.
By DSPy 3.1.x (current as of April 2026), the framework has absorbed GEPA and RLM, a typed-signature system that respects Pydantic models, and the plumbing you actually need in production: caching, tracing, checkpointed optimizer state, MLflow hooks.
GEPA - reflective prompt evolution, instead of RL
If DSPy is the programming model, GEPA is the compiler. Agrawal, Tan, and colleagues at UC Berkeley, Stanford, Databricks, and MIT (ICLR 2026 Oral) show that letting a language model reflect in plain English on why a candidate program failed, then mutating the program's instructions accordingly, closes most of the gap with reinforcement learning. The paper's headline numbers: GEPA outperforms GRPO-style RL by 6% on average and up to 20%, while using up to 35x fewer rollouts. It beats the previous DSPy optimizer, MIPROv2, by over 10% on benchmarks like AIME-2025.
The catch: GEPA only works if your metric can explain why something failed. A metric that returns 0.7 tells the reflection model nothing. A metric that returns "wrong answer; cited doc ['mars'] but the evidence is in ['jupiter']" teaches it everything.
Sidebar: the GEPA acronym. GEPA stands for Genetic-Pareto (paper, DSPy docs, official gepa-ai repo). You'll find a competing expansion, "Genetic-Evolutionary Prompt Adaptation", floating around AI-generated summaries; it doesn't appear in any primary source I could find, so I've been calling it a plausible-sounding LLM hallucination. The "Pareto" part is load-bearing: GEPA keeps a frontier of candidate programs rather than collapsing to one, and that frontier is how it keeps exploring.
RLM - treating long context as an environment, not a payload
Recursive Language Models (Zhang, Kraska, Khattab, Dec 2025) treat the prompt as an environment rather than a payload. Inside a sandboxed Python REPL (DSPy uses Deno + Pyodide WASM), the model writes code to slice, summarize, and recursively sub-query arbitrarily large inputs. The paper's headline result: an RLM built on Qwen3-8B outperforms the base Qwen3-8B by 28.3% on average and approaches GPT-5 on long-context benchmarks, while processing inputs two orders of magnitude beyond the underlying context window.
Alex Zhang's origin blog post frames it well. RLMs separate variable space (what's in the REPL's memory) from token space (what the LM actually sees), and that separation is the real lever for fighting what the field has started calling context rot.
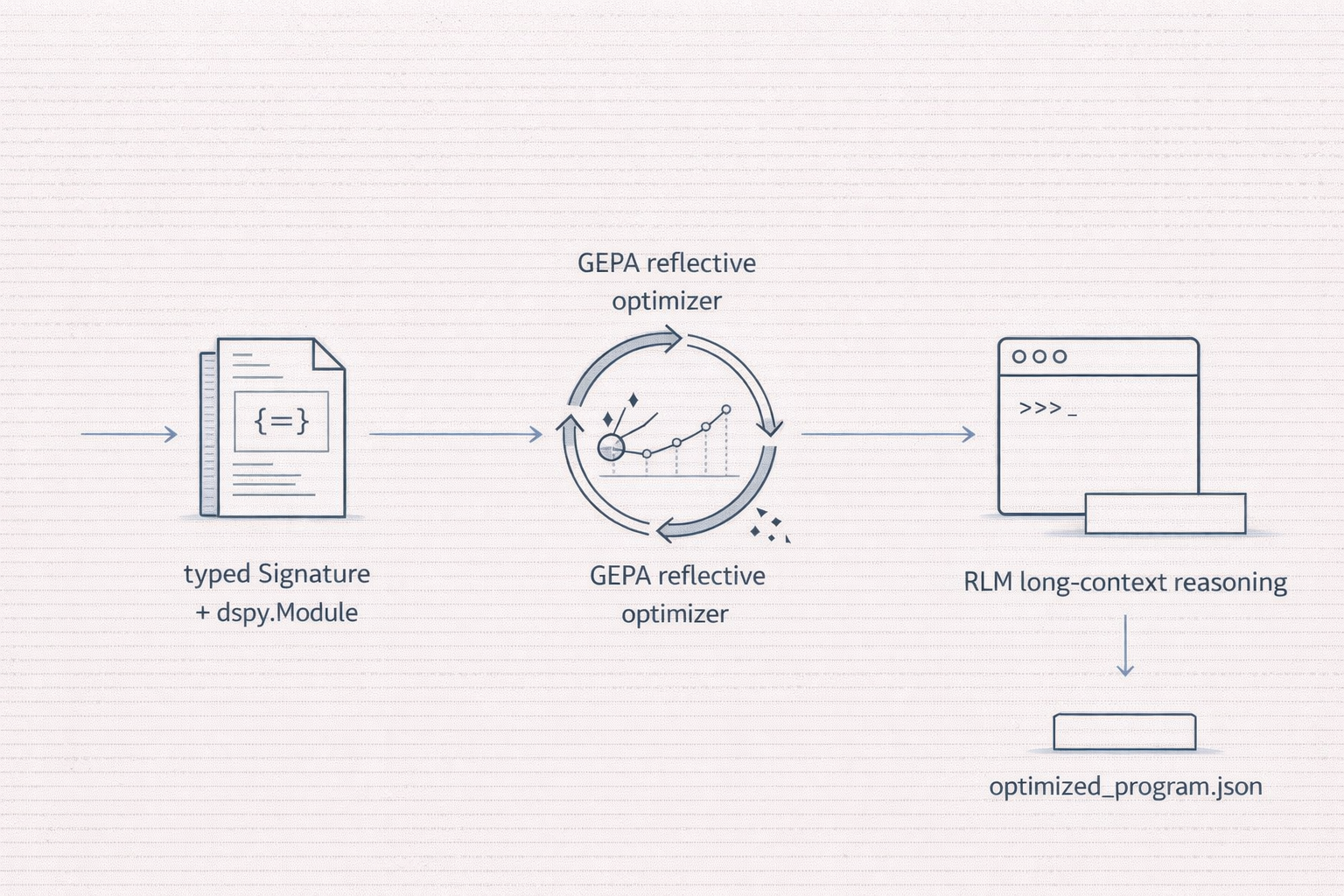
Why a skill pack specifically
Each of those three ideas has a well-written paper, a dedicated docs section on dspy.ai, and the occasional deep-dive blog post. What's missing is the procedural knowledge: the specific incantations that separate "my optimizer ran for four hours and produced nothing" from "my optimizer lifted baseline by 25 points on a 1.2B model."
Agent Skills are the right shape for that kind of knowledge. Simon Willison pointed out that skills are "deliciously tiny": a few hundred bytes of metadata loaded at startup, the full SKILL.md on activation, deeper references on demand. That matches how expert knowledge actually works. You want a quick summary when you need a reminder, deep detail when you're debugging.
The five skills in the pack cover, in order:
dspy-fundamentals. Typed Signatures, Modules, Predict/ChainOfThought/ReAct/ProgramOfThought, save/load. The "what the language even looks like" skill.dspy-evaluation-harness. Rich-feedback metrics that returndspy.Prediction(score=..., feedback=...). Not a dict. (The dict version crashesdspy.Evaluate's parallel aggregator, and yes, I learned this the hard way.)dspy-gepa-optimizer. Full GEPA API with every constructor argument, the compose-your-metric recipe, and why the reflection LM matters more than the task LM.dspy-rlm-module. When to reach for RLM vs. ReAct vs. plain ChainOfThought, how to pair a cheap sub-LM, the Deno dependency.dspy-advanced-workflow. The seven-step loop (spec -> program -> metric -> baseline -> GEPA -> export -> deploy) that orchestrates all four others.
Plus three end-to-end examples that actually show GEPA improving a real metric on free OpenRouter models. More on those in article 3.
The bar I held myself to
Two tests. First, a curious AI engineer clones the repo and can install and smoke-test it in under five minutes on a free-tier API key, without editing source code. (A full GEPA run on the live examples takes more like 20-40 minutes.) Second, every claim in the skills is traceable to an official source: dspy.ai for DSPy, the GEPA paper for optimizer claims, the Claude Code and Codex CLI docs for spec details.
Codex reviewed the repo and found four rounds of subtle errors I'd introduced while drafting. Each round I fixed the specific finding and added a regression test so the issue can't come back. The final test suite has 60 assertions. Most of them exist because I got something wrong the first time.
That process (the Hamel Husain "show me the actual prompt" attitude applied recursively to the documentation) is what made me trust the final output. I recommend applying it when you try the pack yourself.
Where to go from here
If you want to try it, article 2 walks through install and first use in both Claude Code and Codex CLI. If you want the evidence it actually works, article 3 opens up the three validated examples. If you want to know where this is headed, article 4 lays out what composing these pieces makes possible.
For the impatient:
/plugin marketplace add intertwine/dspy-agent-skills
/plugin install dspy-agent-skills@dspy-agent-skills
Then ask your agent: "Use dspy to build a sentiment classifier, optimize it with GEPA, and save the artifact."
If it does something you didn't have to teach it step by step, that's the whole point.



