
Where dspy-agent-skills goes next
Three categories: next examples I'd add, production patterns the skills currently stop short of, and one speculative research idea I'd like to see someone try.

Three categories: next examples I'd add, production patterns the skills currently stop short of, and one speculative research idea I'd like to see someone try.
What's already in v0.1.0
Before the "next" stuff, here's what the current release actually does, end-to-end:
- A new DSPy user can clone the repo, run the examples, and produce a validated optimized program artifact in an afternoon. (Serving that artifact in production is a separate piece of work — see section 3.)
- A coding agent (Claude Code, Codex CLI, or anything else that respects the Agent Skills spec) picks up the DSPy contracts the moment the skills are installed.
- Every claim in the skill pack is traceable to dspy.ai, a paper, or the harness's own spec. Sixty automated tests prevent the kinds of teaching-material drift I hit during the first drafts.
The four sections below are labeled by status: (a) obvious next examples I'd add to the pack, (b) production patterns the skills currently gesture at but don't implement, and (c) one research hypothesis I'd love to see tested, which is explicitly not something this repo does.
1. RLM as a tool inside a GEPA-optimized program (next example)
The dspy-rlm-module skill covers Recursive Language Models standalone: pass a huge document, the RLM writes Python to slice and query it, you get a single answer. The interesting composition happens when RLM becomes one component inside a larger dspy.Module that GEPA optimizes.
class RepoAuditor(dspy.Module):
def __init__(self):
super().__init__()
self.explore = dspy.RLM(
"repo_tree, question -> findings",
max_iterations=30,
sub_lm=dspy.LM("openai/gpt-4o-mini"), # cheap inner model
)
self.synthesize = dspy.ChainOfThought(
"findings, question -> report"
)
def forward(self, repo_tree, question):
f = self.explore(repo_tree=repo_tree, question=question).findings
return self.synthesize(findings=f, question=question)
optimized = dspy.GEPA(metric=rich_metric, ...).compile(
student=RepoAuditor(), trainset=trainset, valset=valset
)
GEPA now has two instruction surfaces to tune: the RLM's exploration prompt and the synthesizer's reporting prompt. The reflection LM can issue targeted feedback to each predictor individually (that's what the pred_name argument to your metric is for). This is the pattern I'd reach for to build a code-review agent, a legal-document analyzer, or an operational-runbook executor. Any task where the input is too large for one prompt and the quality bar is too high for unoptimized reasoning.
The outstanding question for the skill pack: do I ship an opinionated "RLM-inside-GEPA" starter example, or leave the composition as an exercise? My current plan is to wait until I have a real internal use case for it, so the example is grounded rather than theoretical. (If you have one, open an issue.)
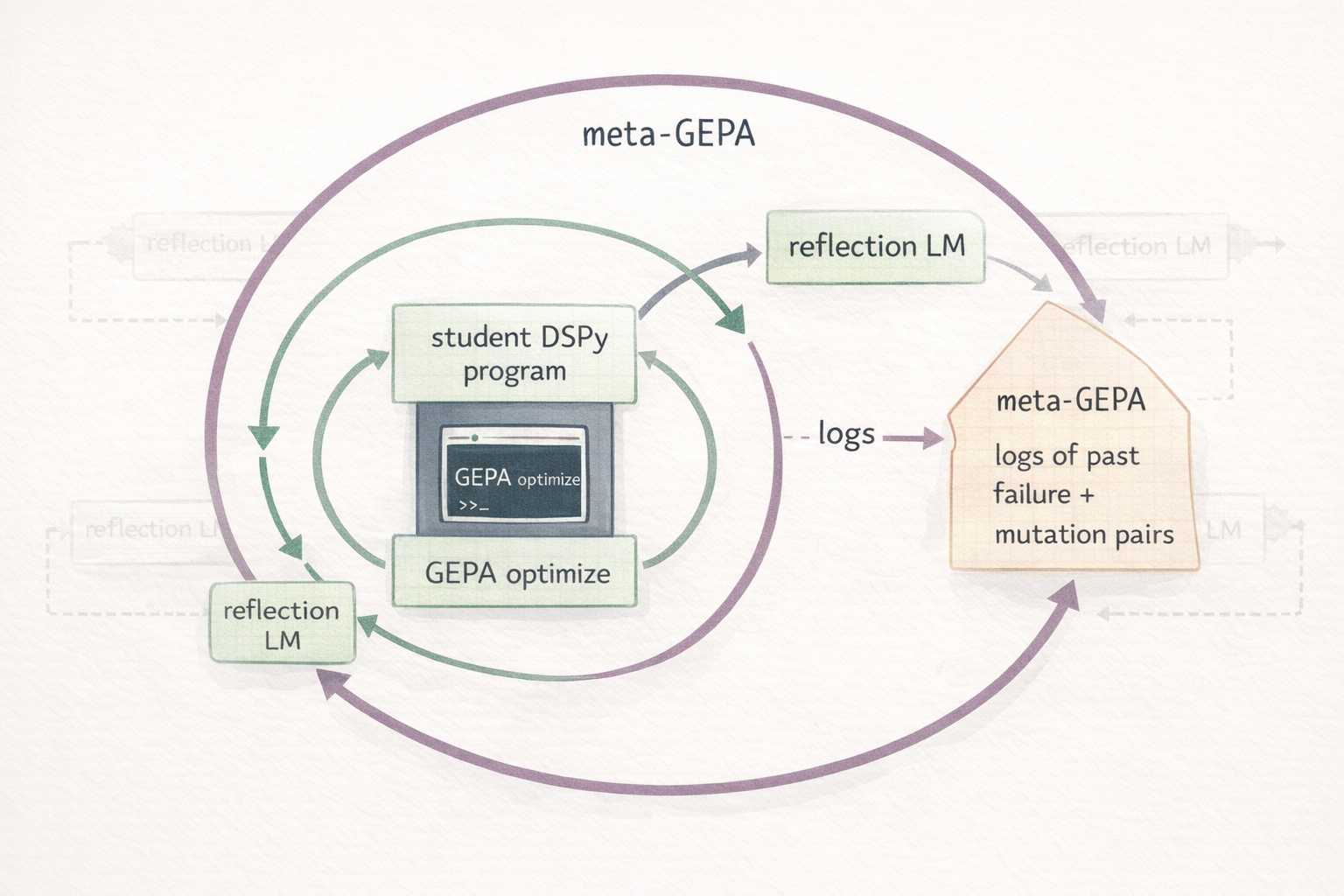
2. GEPA-optimizing the reflection LM itself (research speculation — NOT implemented)
This section is a research hypothesis, not a feature of the current pack. Read it as "here's a thing I'd like to see someone try," not as something that already works.
GEPA's reflection LM reads your metric's feedback and proposes new instructions. Nothing in the protocol requires the task LM and the reflection LM to be the same model. My validated example 02 used a 1.2B task LM with a 120B reflection LM explicitly because the reflection LM needs more capacity than the thing it's teaching.
The speculative extension: could the reflection LM itself be a GEPA-optimized program? A meta-program whose job is "given a student program and its failures, propose better instructions" could in principle be trained on a corpus of (failure, successful-mutation) pairs harvested from real GEPA runs.
I haven't seen this done publicly; I haven't tried it; I don't know whether the economics work out against simply paying for a stronger off-the-shelf reflection model. The GEPA paper's ~35× rollout advantage over RL is what makes me think it might be worth investigating. If anyone does try it, I'd be very interested in the result. Open an issue or ping me.
If it ever becomes practical, a skill would need to cover how to log mutation proposals with enough context to later train on them, how to shape a metric for the meta-task (did the proposed instruction actually lift the student's full-valset score?), and when the complexity pays off versus the off-the-shelf alternative.
3. Production deployment patterns (the skills currently stop here)
The skill pack stops after optimized.save("program.json"). Production starts there. A few patterns I'd add:
Serving. Wrap a DSPy module in FastAPI with the optimized program loaded once at startup, a /v1/predict endpoint, per-request tracing via MLflow's DSPy autolog, and a /healthz that runs a synthetic prediction. The skill would cover the right place to catch DSPy's exceptions, how to surface the structured feedback from a metric as a 4xx vs. 5xx, and how to warm the LM cache before accepting traffic.
Regression harness. A pre-deploy check that runs the committed valset through the candidate program and fails CI below a threshold. This is already pattern-matched by Hamel Husain's "Field Guide to Rapidly Improving AI Products"; the evaluation discipline is what separates shipped AI from hobby AI. Skill deliverable: a drop-in pytest file that reads results.json from a prior optimization and asserts the current program stays within tolerance.
Pareto inference-time selection. GEPA with track_best_outputs=True records the best prediction per task across all candidates. At inference time on a held-out input, you can ensemble or pick the best-on-similar-input candidate. Neither the skill nor the examples use this yet, but the GEPA docs document it and the numbers suggest it's often worth the extra runtime.
Cost and latency observability. dspy.configure(track_usage=True) accumulates token counts on every prediction. Pair it with a lightweight structured logger and you have the same production-eval loop Hamel writes about, except grounded in a formal program rather than an ad-hoc prompt.
4. Ecosystem contributions that would move the needle (open)
Concrete things that don't exist yet, ordered roughly by how much I'd personally use them:
A skill for DSPy fine-tuning. Beyond GEPA's prompt-level optimization, DSPy 3.x supports weight-level optimization (BetterTogether, dspy.Ensemble). A skill covering when fine-tuning is the right tool vs. when GEPA's prompt search exhausts the gains would help a lot of teams make that call correctly.
A dspy-tooling skill. DSPy's ReAct module is great but the skill pack doesn't cover tool-authoring patterns: how to write a tool callable with proper type hints and docstrings so DSPy's introspection actually uses them, how to handle tool-call failures gracefully, when to use ProgramOfThought vs. ReAct vs. RLM for a given shape of problem.
Benchmark parity with the GEPA paper. The paper evaluates on AIME-2025, BIG-Bench Hard, HotpotQA, and IFEval. A community-maintained reproducibility harness that runs the pack's optimizer configurations against those benchmarks would establish a baseline for contributors and catch regressions across DSPy versions. Arize's benchmarking blog is a good template.
Broader harness coverage. The skill pack targets Claude Code and Codex CLI because those are the Agent-Skills-spec implementations I use. The VoltAgent awesome-agent-skills directory lists packs for Gemini CLI and Cursor that work off the same SKILL.md format. I'd like to validate the pack explicitly against those and publish a compatibility matrix.
A examples/04-long-context-rlm/ demo. The only skill without its own dedicated end-to-end example. An RLM demo that exercises a real long document (a Supreme Court decision, a year of commit logs, a novel) would round out the trio of live demos. The constraint: Deno has to be installed, which raises the reproduction friction. I'd rather ship a slightly friction-y example that actually demonstrates the capability than an artificially small one that doesn't.
How to contribute
- Open an issue with your use case. The examples are small deliberately. If you have a real problem that would benefit from one of the composition patterns above, I'd rather build that than invent one.
- PRs welcome for: new skills, new examples, additional harness compatibility, documentation fixes. The test suite enforces the spec rules (no dict metrics, no
.overall_score, every skill has a runnable example with--dry-run), so you'll know quickly if a change breaks a contract. - Simon Willison's piece on agent skills captures the current state of the spec accurately: mostly good, deliberately under-specified, evolving quickly. If the spec changes in a way that matters for DSPy users, I'd like to be among the first to update.
Closing thought
The ideas in this stack are each individually strong: declarative programs over prompts, reflective evolutionary optimization beating RL, recursion beating context-window scaling. What I think is underappreciated is how compositional they are. A typed Signature is a function type. A Module is a function. GEPA is a compiler. RLM is a runtime. Agent Skills are how that runtime gets installed into the user's actual workflow.
The parts fit. The remaining work is almost entirely about making the fit visible to new users faster. That's what I've tried to do in v0.1.0, and it's the axis I'd push next.
If you try the pack, tell me what broke. That's the most useful feedback for anyone building in this space right now.



